In diesem Artikel geht es um die Entwicklung eines Machine Learning Modells. Der technische Fortschritt trägt zu einem starken Anstieg der Systemkomplexität bei. Das manuelle Warten von Maschinen, Systemkomponenten und Produktionslinien wird entsprechend aufwendiger und teurer. Daher nimmt die automatisierte Instandhaltung einen immer höheren Stellenwert in der produzierenden Industrie ein. Das im Folgenden aufgeführte Beispiel eines Machine Learning Modells errechnet auf Basis verschiedener Sensordaten die Wahrscheinlichkeit für einen Maschinenausfall und legt eine entsprechende Instandhaltungsmeldung an. Zudem werden die Maschinendaten und Instandhaltungsmeldungen in einer UI5-Anwendung visualisiert.
Rahmenbedingungen und Scope: SAP Machine Learning Modell
Ziel ist das Trainieren und Evaluieren eines logistischen Modells mithilfe historischer Maschinendaten zur Vorhersage von Maschinenausfällen. Training und Evaluierung finden ausschließlich in ABAP statt. Für die Erzeugung neuer Sensor- bzw. Maschinendaten wird ein per REST-Schnittstelle an das SAP angebundener esp32-Controller mit Temperatur- und Feuchtigkeitssensor verwendet. Die eingehenden Werte werden mithilfe des Machine Learning Modells klassifiziert, um die Ausfallwahrscheinlichkeit zu errechnen. Das Projekt benötigt mindestens NetWeaver 7.4 für die Gateway-Funktionalitäten und UI5-Bibliotheken. Es wird keine SAP Predictive Maintenance- oder Leonardo-Lösung benötigt.
Prozess
Um dies zu erreichen, soll folgender Beispielprozess realisiert werden: Eine Produktionsmaschine erzeugt Daten und überträgt sie per REST-Schnittstelle in das SAP-System. Dort werden sie gespeichert und sowohl zum Training als auch zur Evaluierung eines Machine Learning Algorithmus verwendet. Die Visualisierung der Daten (Ausfallwahrscheinlichkeit, Sensoren, Instandhaltungsmeldungen) erfolgt über eine UI5- bzw. Fiori-Anwendung. 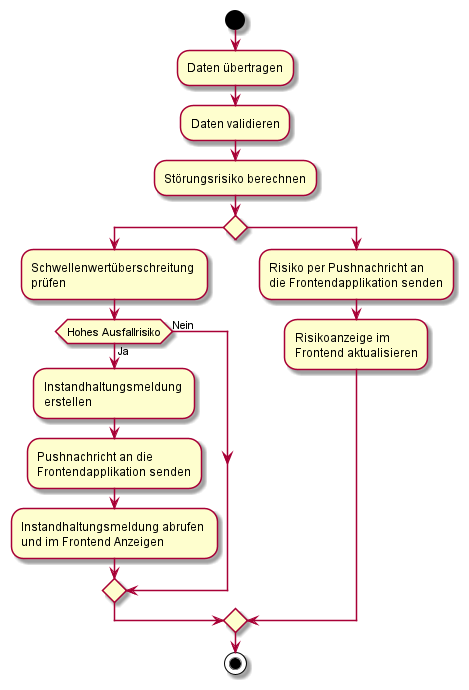
Fiori-Oberfläche
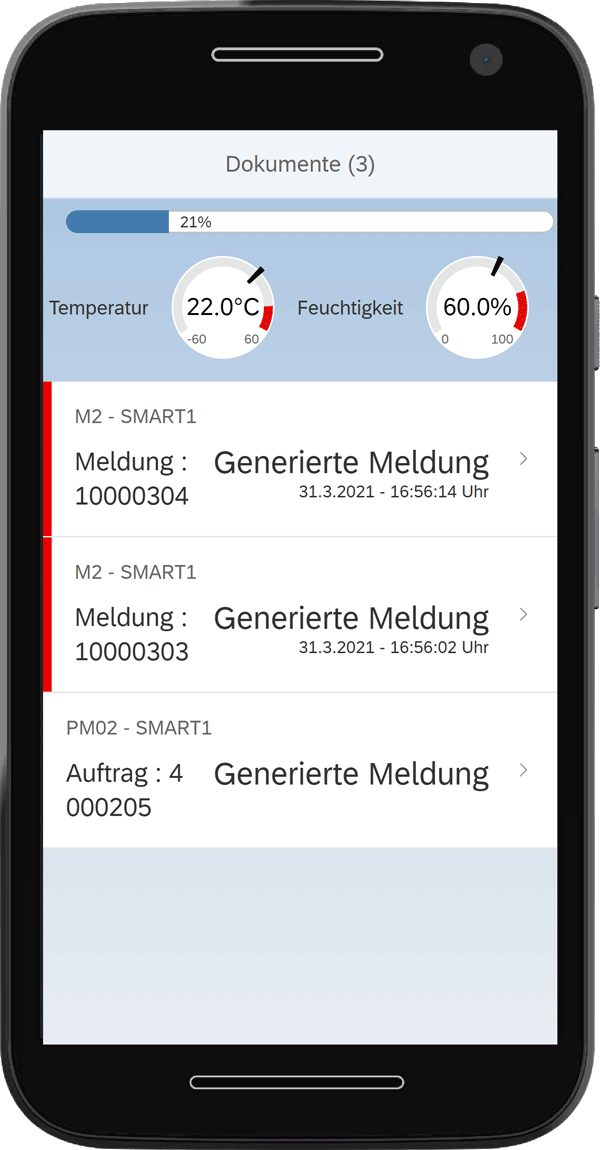
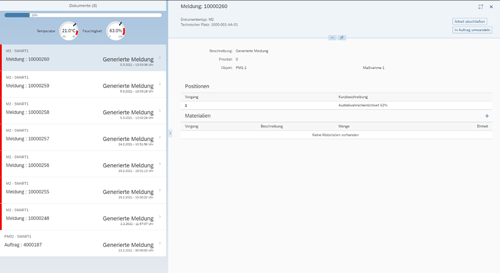
Zur Anzeige der aktuellen Ausfallwahrscheinlichkeit und Sensordaten sowie der derzeitig vorhandenen Instandhaltungsmeldungen, die vom System erzeugt wurden, wird eine Fiori- bzw. UI5-Oberfläche erstellt. Push-Nachrichten sorgen dafür, dass die angezeigten Maschinendaten und Instandhaltungsmeldungen immer aktuell sind.
Was ist logistische Regression?
Mit statistischem bzw. maschinellem Lernen ist es möglich, komplexe Datensätze zu verstehen und komplexe Zusammenhänge zu modellieren. Zu diesem Zweck stehen eine Vielzahl statistischer Modelle und Algorithmen zur Verfügung. Diese haben die Gemeinsamkeit, dass sie auf historischen Daten trainiert werden, um Zusammenhänge zu erlernen. Dadurch können sie Vorhersagen treffen.
Diese Modelle und Algorithmen lassen sich grob in zwei Gebiete einteilen: Überwachtes und unüberwachtes statistisches Lernen. Der Hauptunterschied zwischen diesen Gebieten ist, dass beim überwachten Lernen die Zielvariable bekannt ist. Im Fall der prädiktiven Instandhaltung zum Beispiel stehen typischerweise historische Daten zur Verfügung, die unter anderem die Information beinhalten, wann ein Fehler an der Maschine auftrat, während beim unüberwachten Lernen keine Zielvariable existiert. Dies ist beispielsweise dann der Fall, wenn Netflix versucht Filme nach ihrer Ähnlichkeit zu gruppieren. Im Folgenden findet der Ansatz des überwachten Lernens Anwendung. Spezifischer soll ein Klassifikationsproblem gelöst werden:
Gegeben der aktuellen Sensordaten: Liegt eine maschinelle Störung vor oder nicht?
Störungen erkennen bevor sie eintreten
Nehmen wir an, ein Unternehmen möchte, die in seiner Produktion anfallenden Maschinenstillstände und die damit verbundenen Produktionspausen reduzieren. Dafür ist es notwendig zu wissen, wann eine Störung auftritt, bevor sie eintritt. Oftmals stehen dazu lediglich Messdaten der betroffenen Maschinen zur Verfügung. In diesem Beispiel gehen wir davon aus, dass die Daten in kausalem Zusammenhang stehen. Wüsste die Unternehmung, wann eine Störung besonders wahrscheinlich ist, könnte sie durch Anpassung der Instandhaltungskosten pro Zeiteinheit, die Maschinenausfälle pro Zeiteinheit indirekt beeinflussen. Mithilfe statistischen Lernens kann ein Vorhersagemodell erstellt werden, das die Wahrscheinlichkeit für einen Maschinenstillstand auf Basis der Sensormessdaten vorhersagt. Es soll also ein Vorhersagemodell trainiert werden, das lernt, wie die Vorhersagevariablen (Sensormessdaten) zu kombinieren sind, um bestmöglich eine Wahrscheinlichkeit für die Zielvariable (Maschinenausfälle) vorherzusagen. Da es sich hierbei um die Prognose von Wahrscheinlichkeiten handelt sind diese auf den Wertebereich [0,1] beschränkt. So muss ein statistisches Modell Anwendung finden, das in der Lage ist, den Zusammenhang zwischen Sensormessdaten und Fehlerauftreten zu modellieren. Die logistische Regression ist ein solches Modell. Sie modelliert die Auftrittswahrscheinlichkeit eines Ereignisses (oder einer Klassenzugehörigkeit) durch die lineare Kombination einer oder mehrerer Prädiktoren.
![Logistische Regression [0;1]](https://www.inwerken.de/wp-content/uploads/2021/04/3_logi_kl.png)
Das Modell nimmt mit einem Prädiktor X und einer binären Zielvariable Y, wobei Y = 1 eine Störung angibt, folgende Form an:
![]()
β0 ist der Koeffizient für die Konstante, β1 und β2 sind Koeffizienten der Prädiktoren (Sensordaten) X1 und X2. Auf der linken Seite der Gleichung ist die Ausfallwahrscheinlichkeit (Y=1) in Abhängigkeit der Prädiktoren beschrieben. Die Formel auf der rechten Seite wird immer ein Ergebnis zwischen 0 und 1 sowie eine Kurve in S-Form ausgeben. Ziel ist es nun, die Koeffizienten für die Konstante und die Prädiktoren zu finden, die den wahren Zusammenhang zwischen den Prädiktoren X und der Zielvariable Y bestmöglich abbilden. Modelliert wird also die Wahrscheinlichkeit, dass eine Störung vorliegt.
Sensorwerte als Störungsindikatoren
Generell geht es darum, dass das statistische Modell lernt, welche Sensorwerte eine Störung indizieren. (Pr(Y=1|X) wobei Y=1 eine Störung ist). Die Schätzung der Modellparameter findet hier mithilfe des Gradientenverfahrens statt. Das Modell muss lediglich einmal initial trainiert werden und kann dann als Teil des Geschäftsprozesses implementiert werden. Es empfiehlt sich dennoch, das Modell in regelmäßigen Abständen neu zu trainieren, um bestmögliche Vorhersagequalität zu gewährleisten.
Modelltraining / Schätzung der Koeffizienten
Das initiale Training des Modells erfolgt mithilfe von simulierten Daten im SAP-System. Nach dem Training ist das Modell in der Lage jeden neuen Datenpunkt hinsichtlich der Wahrscheinlichkeit, dass er eine Störung indiziert, zu klassifizieren. Die in der Vergangenheit beobachteten Werte für Temperatur, Luftfeuchtigkeit und Maschinenausfall werden als Trainingsdaten verwendet. Für diesen Fall werden Daten manuell über einen ABAP-Report erzeugt. Diese bestehen hier aus je einem Sensorwert für Temperatur und Luftfeuchtigkeit sowie einer Flag für den Störungsausfall.
Es werden 1000 Datensätze erzeugt, wovon 70 % für das Modelltraining und 30 % für die anschließende Evaluierung verwendet werden. Da ABAP keine Funktionalität für maschinelles Lernen hat, ist die logistische Regression eigenhändig mithilfe des Gradientenverfahrens zu implementieren.
Das Verfahren des Modelltrainings gestaltet sich, wie folgt:
- Als erstes werden die Parameter für die Lernrate und die Anzahl der Iterationen für das Gradientenverfahren festgelegt. Außerdem werden die Schätzwerte für die Koeffizienten definiert (weights und bias).
- Durchlaufen des Gradientenverfahrens auf den Trainingsdaten, für die vorgesehene Anzahl der Iterationen und währenddessen in jeder Iteration:
a.) Vorhersage der Ausfallwahrscheinlichkeit auf Basis der aktuellen Koeffizienten der Konstante und der Prädiktoren. Aus Sensorwerten und den aktuellen Schätzwerten der Koeffizienten wird das Skalarprodukt errechnet (z).
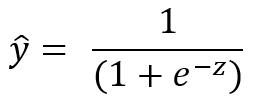
z ist also die Summe aus dem Skalarprodukt des Prädiktorvektors X (Sensormessdaten) und den geschätzten Koeffizienten für die Prädiktoren und der Konstanten.
b.) Transponieren der Trainingsdaten zur Errechnung der Ableitungen dw1, dw2, und db.
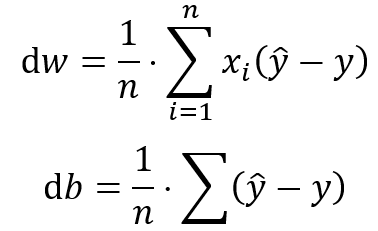
c.) Berechnung der Gradienten für die Konstante und die Koeffizienten auf Basis der aktuellen Schätzungsabweichung von der wahren Ausprägung der Zielvariable.
d.) Aktualisierung der Koeffizienten durch Multiplikation der Gradienten mit der Lernrate. - Wiederholung ab Schritt zwei mit den neuen Schätzwerten, bis die Anzahl der maximalen Durchläufe erreicht wurde.
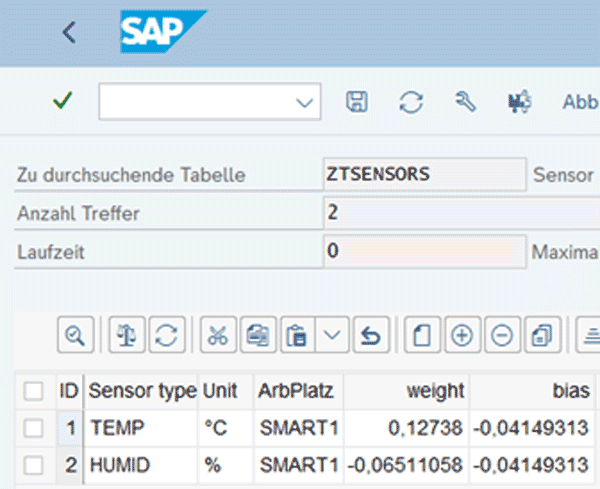
Nach Durchlauf des Trainings werden die Koeffizienten in der Tabelle ZTSENSORS als „weights“ und „bias“ abgelegt. Sie werden, nach Eingang neuer Sensordaten, zur Schätzung der Störungswahrscheinlichkeit herangezogen.
Evaluierung / Prüfen der Modellgüte
Nachdem das Modell der logistischen Regression trainiert wurde, muss die Zuverlässigkeit geprüft werden. Erst im Anschluss ist klar, ob die Modellierung in der Lage ist, zuverlässige Vorhersagen zu treffen.
Die logistische Regression errechnet eine Wahrscheinlichkeit für die Klassenzugehörigkeit (0 = keine Störung, 1 = Störung). Bei einem binären Outcome sind in Bezug auf die Korrektheit der Vorhersage, vier Ergebnisse möglich:
- False Positive: Wenn eine Störung vorhergesagt wurde, die nicht eingetreten ist.
- False Negative: Wenn eine Störung übersehen wurde.
- True Positiv: Wenn eine Störung korrekt vorhergesagt wurde.
- True Negative: Wenn eine vorhergesagte Störung nicht eingetreten ist.
Wird das trainierte Modell auf den Evaluierungsdatensatz angewendet, ergeben sich folgende Werte:
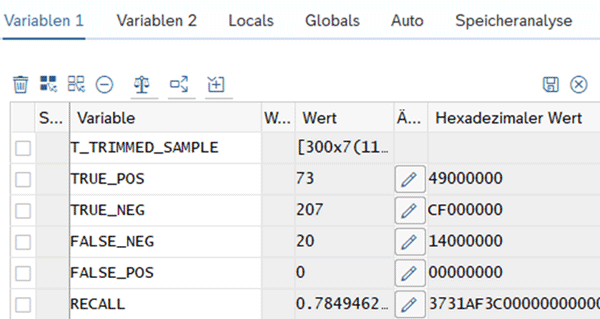
Der Recall-Wert errechnet sich über die Formel unten und gibt an, wie viel Prozent der tatsächlichen Störungen korrekt vorhergesagt wurden. Bei den aktuell gewählten Parametern werden 78 % der Störungen erkannt. Durch das Anpassen der Parameter oder das Hinzufügen weiterer unabhängiger Variablen, kann dieser Wert stetig verbessert werden.
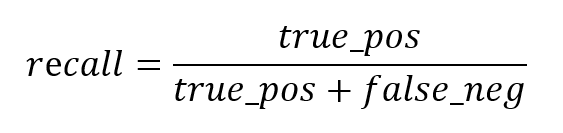
Vorhersage auf Basis neuer Datenpunkte
Nachdem die Koeffizienten erfolgreich geschätzt wurden, können neue Sensorwerte für X1 und X2 in die Formel eingesetzt werden.
![]()
Das Ergebnis ist die Fehlerwahrscheinlichkeit in Prozent.
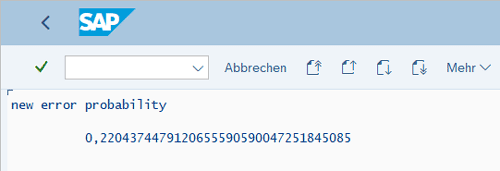
Beispielprozess in SAP
Kontinuierliches Erzeugen von Messwerten für Temperatur und Feuchtigkeit
Um einen realitätsnahen Prozess abzubilden, wird ein esp32-Controller verwendet, um die Sensoren an der Produktionslinie zu simulieren. Ein Sensormodul misst Luftfeuchtigkeit und Temperatur. An dieser Stelle sind beliebige Sensoren denkbar. Der Sensor-Chip schickt alle zehn Sekunden Daten an das SAP-System. Durch den Übertrag wird mit Hilfe des oben trainierten Modells die Ausfallwahrscheinlichkeit errechnet und als Ergebnis auf dem Display des Controllers angezeigt.

Um die Daten im SAP verarbeiten zu können, wird mit Hilfe des SAP-Gateways eine REST-Schnittstelle eingerichtet. Hier gehen die Sensordaten ein und werden dann weiterverarbeitet. Das Event wird im Backend geloggt und die UI5-Clients per Push-Nachricht über die neue Ausfallwahrscheinlichkeit informiert. Bei Überschreitung eines bestimmten Schwellenwertes wird eine Instandhaltungsmeldung angelegt und ebenfalls an das Frontend gemeldet.
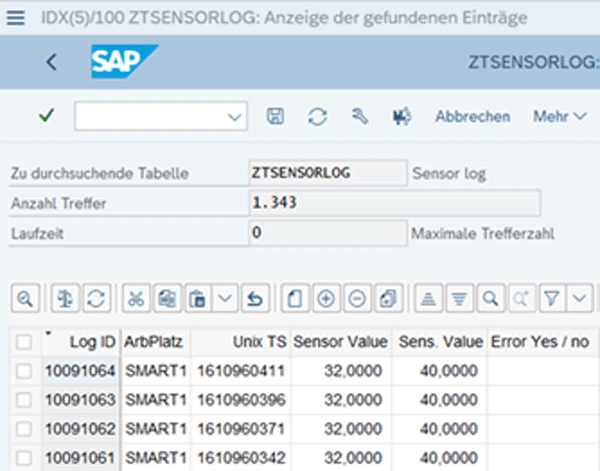
Im Applikationslog wird jeder Sensorping sowie die Reaktion des Modells mitgeschrieben.
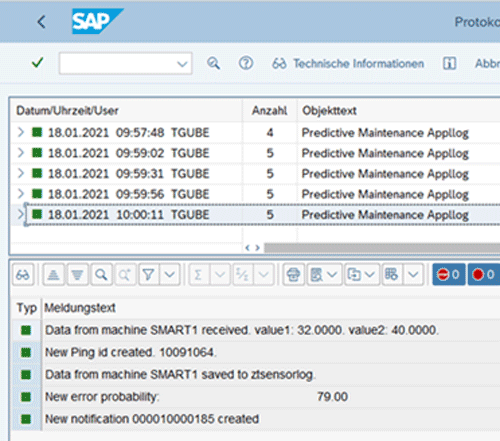
Die UI5-Anwendung wird per Pushnachricht über das Websocketprotokoll über die aktuellen Sensorwerte informiert.
Die stets aktuelle Frontend-Anwendung stellt die Daten entsprechend dar. Im Beispiel unten sind beliebige, weitere Informationen und Funktionen denkbar. So könnten Meldungen in Aufträge umgewandelt, Materialien und Zeiten verbucht oder Aufgaben zugewiesen werden.
Fazit und Ausblick: Logistische Regression
Das SAP-System wird über die vorgesehene SAP-Gateway Schnittstelle für den Eingang der Maschinensensorwerte geöffnet. Diese bilden die Grundlage für das Machine Learning Modell. Durch Modellierung der logistischen Regression in ABAP können diese Sensorwerte so klassifiziert werden, dass sie erfolgreich Maschinenstörungen vorhersagen. Eine browserfähige Frontendanwendung erlaubt das Benachrichtigen der zuständigen Wartungstechniker per Push-Nachricht. Das verwendete Modell der logistischen Regression ermöglicht das Hinzufügen weiterer Sensoren, um sich auf verändernde Produktionsbedingungen einzustellen und um die Vorhersage-Qualität weiter zu verfeinern. Die logistische Regression kann bei ähnlichen Vorhersageproblemen mit binärer abhängiger Variable eingesetzt werden. Die hier präsentierten Ergebnisse beruhen auf den untransformierten Rohdaten. Durch Feature Engineering kann die Genauigkeit der Vorhersagen verbessert und aus den Rohdaten neue Prädiktoren erstellt werden.
Sie haben Fragen zu dem Beitrag von Tobias Gube oder dem Thema Machine Learning?
Kontaktieren Sie uns jederzeit gern. Weitere Informationen finden Sie auch demnächst in unserem Leistungsportfolio.